3) Load Model from Registry
Chapter Preview
목표
- MLflow 에 저장된 모델을 불러올 수 있는 스크립트를 작성합니다.
- 불러온 모델을 통해 추론하고 결과를 확인합니다.
스펙 명세서
- 학습이 끝난 모델을 MLflow built-in method 를 사용하여 MLflow 서버에서 불러옵니다.
- 2) Save Model to Registry 챕터에서 설치한
mlflow패키지를 사용합니다. - 학습에 관련된 정보가 저장 되어있는
run의run_id를 사용하여 모델을 불러옵니다. mlflow패키지를 이용하여 모델을 불러오는 방법은 두 가지가 있습니다.- 이번 챕터에서는
sklearn의 모델을 불러오기 위해mlflow.sklean.load_model을 사용합니다.
- 2) Save Model to Registry 챕터에서 설치한
- 불러온 모델을 이용하여 2) Save Model to Registry 챕터에서 저장해두었던 학습 데이터의 결과를 추론합니다.
해당 파트의 전체 코드는 mlops-for-mle/part3/ 에서 확인할 수 있습니다.
part3
├── Dockerfile
├── Makefile
├── README.md
├── docker-compose.yaml
├── load_model_from_registry.py
└── save_model_to_registry.py
 [그림 3-9] MLflow Model Load Diagram
[그림 3-9] MLflow Model Load Diagram1. 모델 불러오기
2) Save Model to Registry 챕터에서 작성한 코드로 학습된 모델을 서버로부터 불러오는 코드를 작성합니다.1.1 환경 변수 설정
2) Save Model to Registry 챕터와 같이 MLflow 서버에 접근하기 위한 환경 변수를 설정합니다.import os
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://localhost:9000"
os.environ["MLFLOW_TRACKING_URI"] = "http://localhost:5001"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "miniostorage"
1.2 모델 불러오기
1.2.1 sklearn 모델 불러오기
2) Save Model to Registry 챕터에서 저장했던 모델을 불러오기 위해, mlflow.sklearn.load_model 함수를 사용하여 저장된 모델을 불러옵니다. 모델을 포함하고 있는 run_id 와 모델을 저장할 때 설정했던 모델 이름을 받을 수 있도록 외부 변수를 설정합니다.parser = ArgumentParser()
parser.add_argument("--run-id", dest="run_id", type=str)
parser.add_argument("--model-name", dest="model_name", type=str, default="sk_model")
args = parser.parse_args()
앞서 받은 두 가지 변수를 이용해 runs:/run_id/model_name 의 형식으로 문자열을 만들어 줍니다.
만들어진 문자열을 mlflow.sklearn.load_model 의 입력으로 넣고 모델을 불러옵니다.
model_pipeline = mlflow.sklearn.load_model(f"runs:/{args.run_id}/{args.model_name}")
불러온 모델을 확인하면 아래와 같습니다.
print(model_pipeline)
# Pipeline(steps=[('scaler', StandardScaler()), ('svc', SVC())])
1.2.2 pyfunc 모델 불러오기
MLflow 에서는 지정한 방식 [MLFlow Storage Format]에 따라 저장되어있는 모델에 대해서는 종류에 관계없이 mlflow.pyfunc.load_model 을 이용하여 쉽게 모델을 불러올 수 있습니다.
이 때 로드된 모델은 기존의 클래스가 아닌 mlflow.pyfunc.PyFuncModel 클래스로 불러와집니다. PyFuncModel 이란 mlflow 에서 정의된 새로운 클래스로, 결과 추론을 위해 학습한 모델의 predict method 를 호출하도록 wrapping 된 클래스입니다.
model_pipeline = mlflow.pyfunc.load_model(f"runs:/{args.run_id}/{args.model_name}")
마찬가지로 앞서 받은 두 가지 변수를 형식에 맞춰 mlflow.pyfunc.load_model 의 입력으로 넣어 모델을 로드합니다.
불러와진 모델을 확인하면 아래와 같습니다.
print(model_pipeline)
# mlflow.pyfunc.load_model:
# artifact_path: sk_model
# flavor: mlflow.sklearn
# run_id: `RUN_ID`
1.3 추론 코드 작성하기
2) Save Model to Registry 챕터에서 저장했던 데이터인data.csv 파일로부터 데이터를 불러옵니다.df = pd.read_csv("data.csv")
학습 조건과 같도록 불필요한 columns 를 제거하고, 학습 데이터와 평가 데이터로 분리합니다.
X = df.drop(["id", "timestamp", "target"], axis="columns")
y = df["target"]
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, random_state=2022)
train_pred = model_pipeline.predict(X_train)
valid_pred = model_pipeline.predict(X_valid)
train_acc = accuracy_score(y_true=y_train, y_pred=train_pred)
valid_acc = accuracy_score(y_true=y_valid, y_pred=valid_pred)
print("Train Accuracy :", train_acc)
print("Valid Accuracy :", valid_acc)
# Train Accuracy : 0.95
# Valid Accuracy : 0.95
2. 전체 코드 완성
추가 작성한 코드를 전체 코드에 적용하여 완성합니다.
2.1 load_model_from_registry.py
# load_model_from_registry.py
import os
from argparse import ArgumentParser
import mlflow
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# 0. set mlflow environments
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://localhost:9000"
os.environ["MLFLOW_TRACKING_URI"] = "http://localhost:5001"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "miniostorage"
# 1. load model from mlflow
parser = ArgumentParser()
parser.add_argument("--model-name", dest="model_name", type=str, default="sk_model")
parser.add_argument("--run-id", dest="run_id", type=str)
args = parser.parse_args()
model_pipeline = mlflow.sklearn.load_model(f"runs:/{args.run_id}/{args.model_name}")
# 2. get data
df = pd.read_csv("data.csv")
X = df.drop(["id", "timestamp", "target"], axis="columns")
y = df["target"]
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, random_state=2022)
# 3. predict results
train_pred = model_pipeline.predict(X_train)
valid_pred = model_pipeline.predict(X_valid)
train_acc = accuracy_score(y_true=y_train, y_pred=train_pred)
valid_acc = accuracy_score(y_true=y_valid, y_pred=valid_pred)
print("Train Accuracy :", train_acc)
print("Valid Accuracy :", valid_acc)
2.2 실행 및 결과 확인
localhost:5001 에 접속하여 저장된 모델의
run을 클릭하여run_id와model_name을 확인합니다.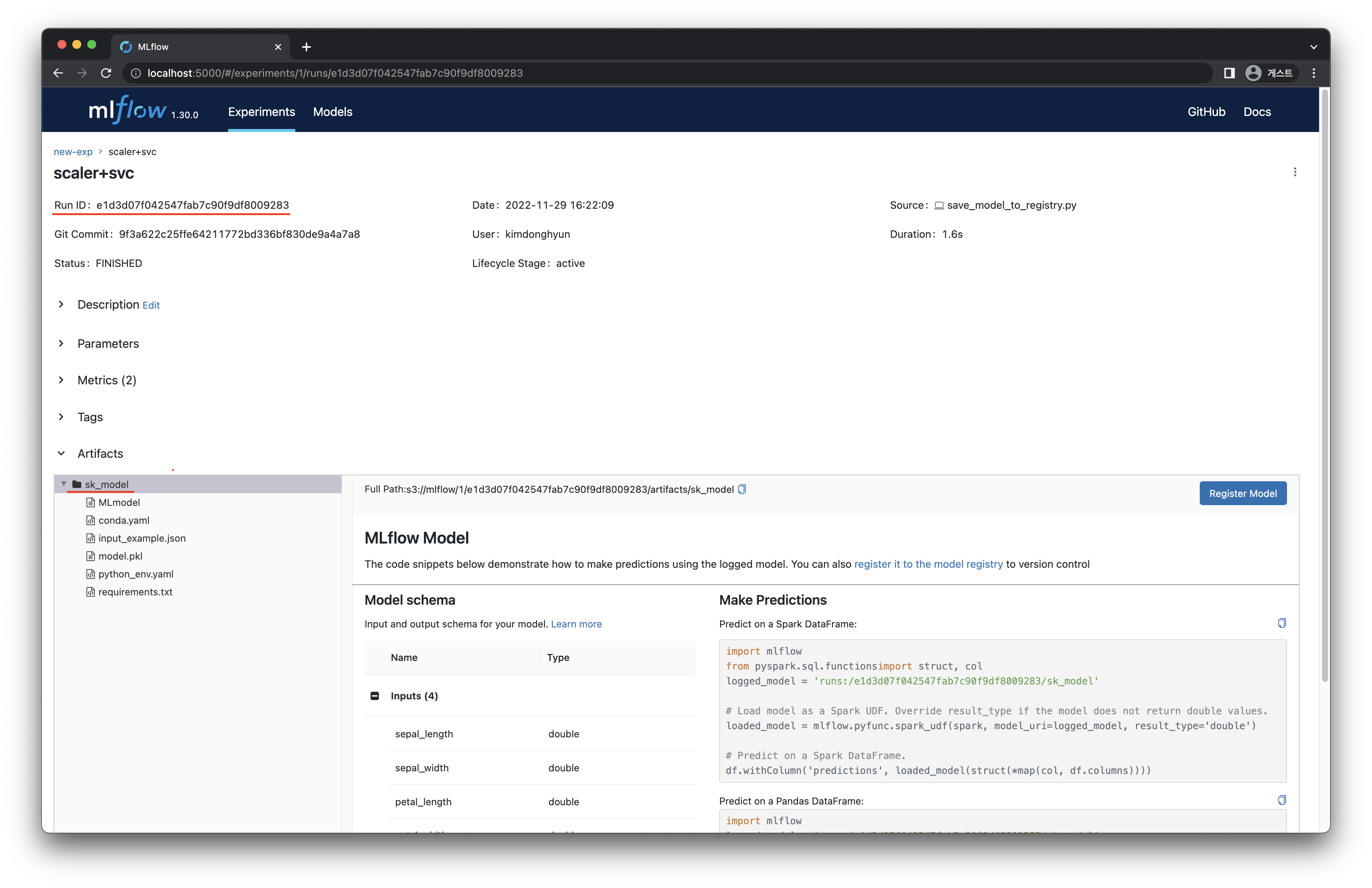 [그림 3-10] run-id 및 model-name 확인
[그림 3-10] run-id 및 model-name 확인아래 코드의
--model-name,--run-id뒤에 해당 값을 사용하여 실행합니다.python load_model_from_registry.py --model-name "sk_model" --run-id "RUN_ID"MLflow 서버의 metrics 를 확인하여 학습했던 결과와 같은지 확인합니다.
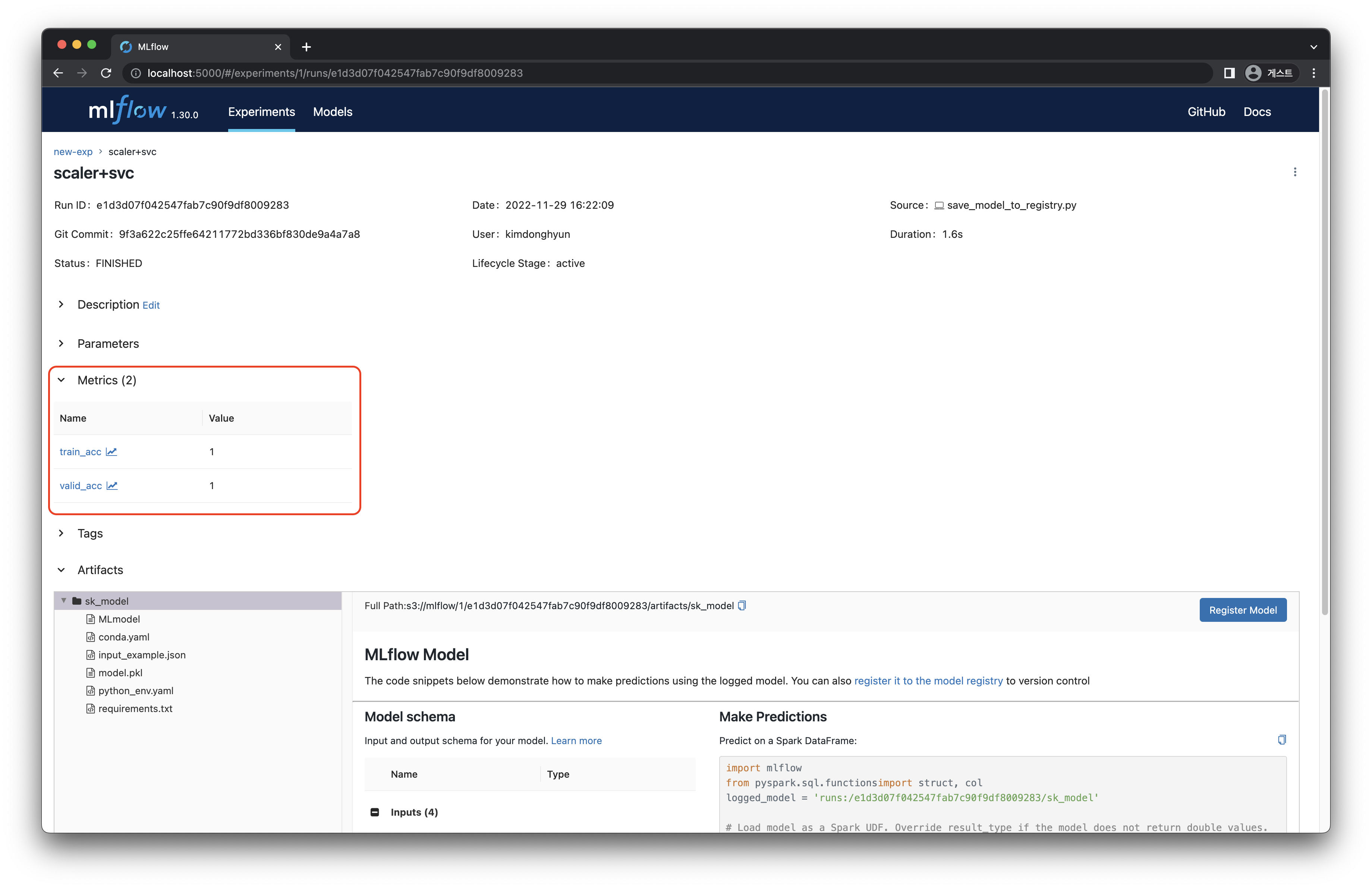 [그림 3-11] 모델 추론 결과 확인
[그림 3-11] 모델 추론 결과 확인