3) Load Data from Database
Chapter Preview
목표
- DB 에서 데이터를 가져오는 파이프라인을 작성합니다.
스펙 명세서
- 데이터 불러오기
- 01. Database 파트에서 생성한 DB 에서 데이터를 가져옵니다.
idcolumn 을 기준으로 최신 데이터 100개를 추출하는 쿼리문을 작성합니다.pandas.read_sql함수를 이용해 데이터를 추출합니다.
- 모델 파이프라인 수정
- 1) Base Model Development 챕터에서 작성한 파이프라인 중 데이터를 불러오는 부분을 위에서 작성한 함수로 수정합니다.
- 모델을 학습하고 저장합니다.
- 저장된 모델이 정상적으로 동작하는지 확인합니다.
해당 파트의 전체 코드는 mlops-for-mle/part2/ 에서 확인할 수 있습니다.
part2
├── Makefile
├── README.md
├── base_train.py
├── base_validate_save_model.py
├── db_train.py
├── db_validate_save_model.py
├── pipeline_train.py
└── pipeline_validate_save_model.py
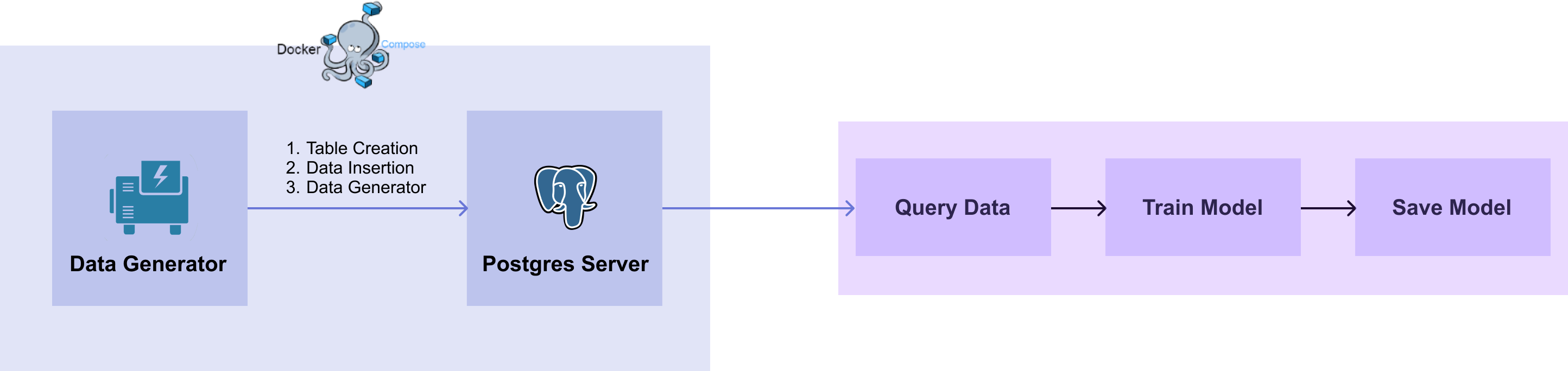 [그림 2-2] Database Workflow
[그림 2-2] Database Workflow
📌 해당 챕터는 01. Database 파트의 DB 를 이용합니다.
📌 DB 를 띄우지 않은 경우 01. Database 파트를 완료하고 DB 가 띄워진 상태에서 진행해주세요.
1. Load Data
1.1 Query
id column을 기준으로 최신 데이터 100개를 추출하는 쿼리문을 작성합니다.
SELECT * FROM iris_data ORDER BY id DESC LIMIT 100;
psql 에서 해당 쿼리문을 입력하면 다음과 같이 출력됩니다.
mydatabase=# SELECT * FROM iris_data ORDER BY id DESC LIMIT 100;
id | timestamp | sepal_length | sepal_width | petal_length | petal_width | target
-----+----------------------------+--------------+-------------+--------------+-------------+--------
1 | 2023-01-15 06:08:58.995035 | 6.8 | 2.8 | 4.8 | 1.4 | 1
2 | 2023-01-15 06:09:00.033342 | 6.3 | 2.5 | 5 | 1.9 | 2
3 | 2023-01-15 06:09:01.063739 | 6.3 | 3.3 | 4.7 | 1.6 | 1
4 | 2023-01-15 06:09:02.098688 | 6.3 | 3.3 | 4.7 | 1.6 | 1
5 | 2023-01-15 06:09:03.131971 | 5 | 3.2 | 1.2 | 0.2 | 0
(...)
1.2 Pandas
pandas.read_sql 는 입력 argument 로 query 와 DB connector 를 받습니다.
PostgreSQL DB 에 연결할 수 있는 DB connector 를 생성 후 query 와 DB connector 를 이용하여 데이터를 불러옵니다. DB 에 연결하기 위한 정보는 01. Database 파트의 6) Data Generator on Docker Compose 챕터에서 DB 서버를 생성할 때 입력한 값입니다.
import pandas as pd
import psycopg2
db_connect = psycopg2.connect(host="localhost", database="mydatabase", user="myuser", password="mypassword")
df = pd.read_sql("SELECT * FROM iris_data ORDER BY id DESC LIMIT 100", db_connect)
- db connect
- host :
localhost - database :
mydatabase - user :
myuser - password :
mypassword
- host :
추출된 데이터를 확인하면 다음과 같습니다.
print(df.head(5))
# id timestamp sepal_length sepal_width petal_length petal_width target
# 0 1204 2023-01-15 06:29:35.214374 7.2 3.2 6.0 1.8 2
# 1 1203 2023-01-15 06:29:34.196810 5.0 3.5 1.3 0.3 0
# 2 1202 2023-01-15 06:29:33.184427 5.9 3.0 4.2 1.5 1
# 3 1201 2023-01-15 06:29:32.163934 6.4 3.1 5.5 1.8 2
# 4 1200 2023-01-15 06:29:31.138341 5.8 2.7 5.1 1.9 2
base_train.py 의 # 1. get data 부분을 위에서 작성한 코드로 수정합니다.# db_train.py
import pandas as pd
import psycopg2
from sklearn.model_selection import train_test_split
# 1. get data
db_connect = psycopg2.connect(host="localhost", database="mydatabase", user="myuser", password="mypassword")
df = pd.read_sql("SELECT * FROM iris_data ORDER BY id DESC LIMIT 100", db_connect)
X = df.drop(["id", "timestamp", "target"], axis="columns")
y = df["target"]
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, random_state=2022)
2. Save Data
이어서 사용한 데이터를 저장하는 # 4. save data 부분을 추가합니다.
데이터를 저장하는 이유는 현재 DB 에 계속해서 데이터가 쌓이고 있기 때문에 매번 데이터를 불러올 때마다 데이터가 바뀝니다.
데이터가 바뀌면 모델이 정상적으로 불러왔는지 확인할 수 없기 때문에 사용한 데이터를 저장하여 평가하는 부분에서 사용합니다.
# 4. save data
df.to_csv("data.csv", index=False)
3. 전체 코드
3.1 db_train.py
위에서 작성한 내용을 모아서 db_train.py 로 작성하면 아래와 같습니다.
# db_train.py
import joblib
import pandas as pd
import psycopg2
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
# 1. get data
db_connect = psycopg2.connect(host="localhost", database="mydatabase", user="myuser", password="mypassword")
df = pd.read_sql("SELECT * FROM iris_data ORDER BY id DESC LIMIT 100", db_connect)
X = df.drop(["id", "timestamp", "target"], axis="columns")
y = df["target"]
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, random_state=2022)
# 2. model development and train
model_pipeline = Pipeline([("scaler", StandardScaler()), ("svc", SVC())])
model_pipeline.fit(X_train, y_train)
train_pred = model_pipeline.predict(X_train)
valid_pred = model_pipeline.predict(X_valid)
train_acc = accuracy_score(y_true=y_train, y_pred=train_pred)
valid_acc = accuracy_score(y_true=y_valid, y_pred=valid_pred)
print("Train Accuracy :", train_acc)
print("Valid Accuracy :", valid_acc)
# 3. save model
joblib.dump(model_pipeline, "db_pipeline.joblib")
# 4. save data
df.to_csv("data.csv", index=False)
3.2 validate_save_model.py
다음은 2) Model Pipeline 챕터에서 저장된 모델을 검증하는 base_validate_save_model.py 를 수정해 db_validate_save_model.py 로 저장합니다.
그리고 # 1. reproduce data 에서 저장된 데이터를 불러오도록 수정합니다.
# db_validate_save_model.py
import joblib
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# 1. reproduce data
df = pd.read_csv("data.csv")
X = df.drop(["id", "timestamp", "target"], axis="columns")
y = df["target"]
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, random_state=2022)
# 2. load model
pipeline_load = joblib.load("db_pipeline.joblib")
# 3. validate
load_train_pred = pipeline_load.predict(X_train)
load_valid_pred = pipeline_load.predict(X_valid)
load_train_acc = accuracy_score(y_true=y_train, y_pred=load_train_pred)
load_valid_acc = accuracy_score(y_true=y_valid, y_pred=load_valid_pred)
print("Load Model Train Accuracy :", load_train_acc)
print("Load Model Valid Accuracy :", load_valid_acc)